
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 포스코 AI교육
- 그리디
- 다이나믹프로그래밍
- 딥러닝
- 자료구조
- 코테
- bfs문제
- 코테 문제
- 삼성코테
- 포스코 교육
- DP
- 포스코 ai 교육
- tflite
- 컴퓨팅사고
- 초소형머신러닝
- sort
- 삼성역테
- 삼성코딩테스트
- TensorFlow Lite
- 코딩테스트
- 영상처리
- 임베디드 딥러닝
- 삼성역량테스트
- MCU 딥러닝
- DP문제
- 알고리즘
- tinyml
- dfs문제
- BFS
- dfs
- Today
- Total
코딩뚠뚠
[머신러닝 공부] Graph Representation learning 2 본문
이전포스팅에서 GNN 에서의 graph embedding 이란, 그 이유, 인코더의 종류 , similarity function에 대해서 알아보았다.
[머신러닝 공부] 딥러닝/GNN - 1
인턴에서 GNN을 이용한 Situation Recognition을 수행하며 Graph Neural Network 야 말로 진정한 AI가 아닐까? 라는 생각이 들어 관심이 생겼다. 아래는 GNN을 이용한 상황인식을 하는데 참고한 논문 링크이다.
dbstndi6316.tistory.com
이번에는 중요한 Random Walk Optimization 부터 다시 시작해보고자 한다.
Random Walk Optimization
graph domain에서 feature learning의 의미는 latent space 에서의 node embedding을 찾는 것
실제 graph에서 가깝다면 latent space 상에서도 가깝도록 embedding 해야한다.
| Nr(u) : random walk strategy R로부터 얻을 수 있는 u 의 neighborhood |
G = (V,E)가 있을 때 feature learning의 목표는 mapping function z:u -> R^d를 학습하는 것이다.
이 때 objective function은 이와 같다. (node의 neighborhood를 예측하는 방향으로 학습한다.)
(Objective function >= Cost function >= Loss function)
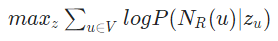
과정
1. graph의 각 node에서 정해진 길이만큼의 random walk를 수행한다.
2. 각 node의 neighborhood Nr(u)를 수집한다.
3. node u가 주어질 때 그 node의 neighborhood Nr(u)를 잘 예측하는 방향으로 node를 embedding 한다.
Loss function

P(v|Zu)는 vector representation이 softmax를 거친 이후의 값이다.
=> node u와 가장 유사도가 높은 node v를 얻기 위함

Loss function을 풀어서 해석하면 아래와 같다.

graph의 모든 node에 대해, 각 node의 neighborhood가 random walk시에 동시에 발견될 확률이 높도록 embedding을 학습한다.
하지만 exp(Zu^T x Zv) 부분 때문에 이 과정은 computation측면에서 매우 expensive 하다
=> 근사하여 문제를 해결한다. Negative Sampling 이 그 방법
Negative Sampling
위의 Loss function 에서 log 안의 함수를 근사한다.
모든 node 를 고려 -> random으로 sampling한 k개의 samples에 대해서만 normalize한다.
random walk는 시작점에서 출발하여 고정된 길이만큼 나아가는 조건으로 시행된다.
그렇기 때문에 비슷하지만 멀리 떨어져 있는 경우에는 그 유사성을 담지 못한다.
또한 random하기 때문에 graph의 전체 구조를 고려하지 못한다는 단점이 존재한다.
이에 node2vec 을 사용할 수 있다.
Random walk, Deep walk, node2vec 등의 방법이 있다.
node2vec 요약

좁은지역 고려 : BFS
넓은지역 고려 : DFS
Biased 2nd-order random walk를 사용한다.
1. random walk probability를 계산
2. graph의 각 node u에 대해 길이 l만큼의 random walk를 한다
3. node2vec를 SGD로 최적화한다.
Reference
아래는 공부하고 포스팅을 하는데 참고한 유튜브 채널과 블로그이다
www.youtube.com/watch?v=zCEYiCxrL_0
www.youtube.com/watch?v=4PTOhI8IWTo&t=293s
velog.io/@minjung-s/GNN-Graph-Representation-Learning-Deep-Walk-node2vec
'공부 > ML&DL' 카테고리의 다른 글
| [머신러닝 공부] 딥러닝/U-Net (0) | 2021.04.03 |
|---|---|
| [머신러닝 공부] 딥러닝/GNN (Graph Neural Network) (0) | 2021.04.03 |
| [머신러닝 공부] Graph Representation learning 1 (0) | 2021.04.03 |
| [머신러닝 공부] 딥러닝 평가지표의 종류 (0) | 2021.04.01 |
| [머신러닝 공부] 머신러닝 딥러닝 확실한 차이 (2) | 2021.03.29 |



