
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- BFS
- dfs
- DP
- 영상처리
- 삼성역량테스트
- 코테
- bfs문제
- 포스코 교육
- 초소형머신러닝
- 딥러닝
- 삼성역테
- 코테 문제
- MCU 딥러닝
- dfs문제
- tflite
- 코딩테스트
- 알고리즘
- TensorFlow Lite
- 포스코 AI교육
- 그리디
- 컴퓨팅사고
- 다이나믹프로그래밍
- 포스코 ai 교육
- sort
- 삼성코테
- 자료구조
- DP문제
- 임베디드 딥러닝
- 삼성코딩테스트
- tinyml
- Today
- Total
코딩뚠뚠
[POSCO 교육 사전학습] 머신러닝기법과 R프로그래밍 8 본문
포스코 포스텍에서 제공하는 청년 AI-BigData 아카데미 과정의 온라인 예습 과정 중 하나인 데이터 과학에 대한 강의를 듣고 정리한 포스팅이다.
청년 AI·Big Data 아카데미 온라인 기초과정 (MOOC)
취업 준비생 누구나 POSTECH과 POSCO가 제공하는 무료 온라인 교육 과정에 참여할 수 있습니다.
pabi.smartlearn.io
머신러닝 기법의 마지막 과정이다.
이번 장에서는 딥러닝과 텍스트마이닝을 배울수 있었다.
차례 : 딥러닝과 텍스트마이닝
- Neural Networks
- Convolutional Neural Networks
- 텍스트마이닝
Neural Networks
인공신경망 (Neural Network) 은 머신러닝의 분류 중 통계적 학습 알고리즘 중 하나이다.
컴퓨터비전(CV), 자연어처리(NLP), 음성인식 등의 영역에서 활발하게 사용된다.
신경망 모델은 Perceptron을 한 단위로 하는 네트워크를 구축하여 인간의 신경세포와 유사한 기능을 하도록 제안됨.
아래 포스팅에서 머신러닝과 딥러닝 차이에 대해 설명해놓았다.
[머신러닝 공부] 머신러닝 딥러닝 확실한 차이
머신러닝과 딥러닝의 확실한 차이를 확실히 알아보려 한다. 대부분 '머신러닝과 딥러닝 차이' 검색어를 치면 아래 사진과 같이 나온다. 나는 이 그림만 보고는 대체 머신러닝과 딥러닝이 뭐가
dbstndi6316.tistory.com
Perceptron (Single Layer)

- 하나의 perceptron 은 단순히 다수의 입력들 (x1 ...) 과 가중치의 선형결합을 계산하는 역할을 수행한다
- Activation 함수에 따라 선형결합으로 생성되는 출력의 값이 결정된다.
- Activation 함수는 Sigmoid 및 ReLU, tanh 등을 사용한다.
Multi-layer perceptron
Single Layer 들이 Multi-layer를 만든다.

- 맨 처음의 Input layer와 마지막의 Output layer 사이에는 Hidden layer가 존재하여 Non-linear transform을 수행한다.
R에서 신경망 모델을 사용하기 위해 mxnet 패키지를 사용한다.
CNN (Convolutional Neural Networks)
하나의 이미지는 수많은 픽셀들이 모여 형성하고 있으며 특정 색과 값을 가진다.
따라서 이미지의 모든 픽셀값들을 입력값으로 갖는 신경망 모델을 만들 수 있다.
but
고해상도 이미지의 경우 feature 의 수가 너무 많아져 fully connected 로 모델 학습에 어려움이 있음
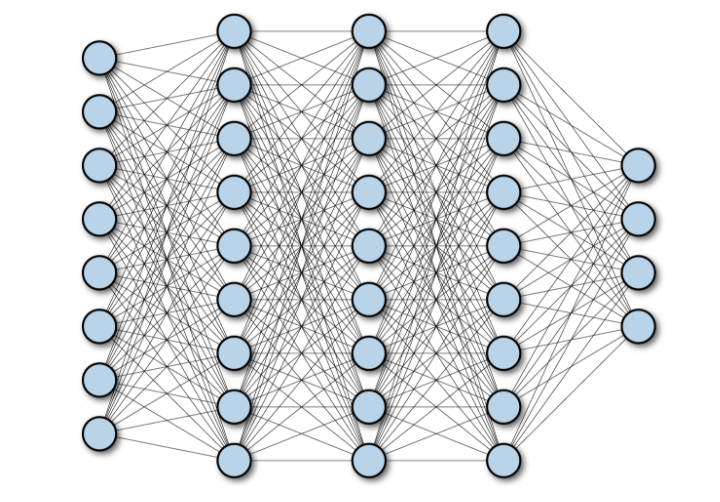
이미지의 일부 특성 feature 만 연결될 수 있는 구조가 더 적합하다.

Image 가 Filter를 거쳐 Output 으로 나오게 되는 구조인데 Filter가 움직이는데 필요한 파라미터들을 설정해줘야 한다. Stride와 filter size , depth 등이 있다.
Pooling layer를 넣어주는 방법이 사용된다.
- 추출해낸 이미지에서 지역적인 부분의 특징만을 뽑아 다음 layer로 넘겨준다.
- 이를통해 가중치들의 수를 줄일 수 있으며 과적합을 방지할 수 있다.
- 대표적으로 큰 값만을 뽑아내는 Max pooling 이 많이 사용된다.
R에서 MNIST 데이터를 이용하여 CNN을 해볼 수 있었다.
텍스트 마이닝
웹페이지 이메일 소셜네트워크 기록 등에서 단어를 추출하여 분석하는 방법으로 트렌드나 관심어를 찾아내는 기법으로 사용된다.
R에서 텍스트마이닝을 위해 필요한 패키지는 NLP 이다.
이론보다는 R에서 NLP 패키지를 사용하는 방법을 소개해주었다.
- tm_map 으로 문장부호를 없애는 텍스트 전처리를 할 수 있다.
- stopword 리스트를 만들어 제거할 수 있다.
- TermDocumentMatrix로 문서행렬을 구성할 수 있다.
- as.matrix 로 문서행렬을 행렬로 변환할 수 있다.
- sort 로 단어의 빈도 순서대로 정렬할 수 있다.
빈도가 높은 단어부터 색상을 넣을 수도 있다.
'공부 > POSCO AI-Big Data 아카데미 14기' 카테고리의 다른 글
| [POSCO 교육 사전학습] 특강/Computer Vision입문 (0) | 2021.04.07 |
|---|---|
| [POSCO 교육 사전학습] 특강/AI입문 (0) | 2021.04.07 |
| [POSCO 교육 사전학습] 머신러닝기법과 R프로그래밍 7 (0) | 2021.04.04 |
| [POSCO 교육 사전학습] 머신러닝기법과 R프로그래밍 6 (0) | 2021.04.04 |
| [POSCO 교육 사전학습] 머신러닝기법과 R프로그래밍 5 (0) | 2021.04.04 |
