
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 그리디
- 포스코 교육
- DP
- DP문제
- tflite
- 삼성코딩테스트
- MCU 딥러닝
- sort
- 삼성역량테스트
- BFS
- 포스코 ai 교육
- dfs문제
- tinyml
- 삼성코테
- 영상처리
- 자료구조
- 코테 문제
- 다이나믹프로그래밍
- 삼성역테
- 코딩테스트
- 초소형머신러닝
- 알고리즘
- 컴퓨팅사고
- 임베디드 딥러닝
- 딥러닝
- dfs
- 포스코 AI교육
- TensorFlow Lite
- bfs문제
- 코테
- Today
- Total
코딩뚠뚠
[머신러닝 공부] Tiny ML -16 / 인체감지 모델 훈련하기 본문
Chapter16. 인체감지 모델 훈련하기
"
이전장까지 썼던 모델 을 훈련시켜보자
"
목차 :
- 연산 환경 선택
- Google Cloud Platform 설정
- 프레임워크선택
- 데이터셋 구축
- 모델 훈련과 평가
- 텐서플로 라이트
- 기타
이전장 링크
[머신러닝 공부] Tiny ML -15 / 인체감지 어플리케이션-3
Chapter15. 인체감지 어플리케이션 " 카메라로 인체를 감지해보자 (CNN) " 목차 : 개요 -> Tiny ML -13 만들고자하는 -> Tiny ML -13 어플리케이션 아키텍처 -> Tiny ML -13 코드 기본흐름 -> Tiny ML -14 핵..
dbstndi6316.tistory.com
참고 repo
GitHub - tensorflow/tensorflow: An Open Source Machine Learning Framework for Everyone
An Open Source Machine Learning Framework for Everyone - GitHub - tensorflow/tensorflow: An Open Source Machine Learning Framework for Everyone
github.com
연산 환경 선택 :
모델의 훈련은 Sparkfun Edge와 같은 MCU 환경에선 불가능과 마찬가지이다.
거의 모든 모델의 훈련은 GPU로 진행하는데, Local 환경 구성이 불가능하다면,
구글의 Colab, 구글 클라우드 플랫폼(GCP), AWS, Azure 등을 사용할 수 있다.

Google Cloud Platform 설정 -> 가격문제로 사용 X :
1. console.cloud.google.com 에 로그인
2. 각종 항목들을 동의하고 프로젝트를 생성한다
3. 프로젝트에 접근해서 Compute Engine -> VM인스턴스 클릭

4. Compute Engine API를 ENABLE 시켜준다. (몇 분 걸린다)
5. 노트북 생성
- AI Platform - Workbench 로 접근한다
- 이후 새 노트북 - Customize 선택
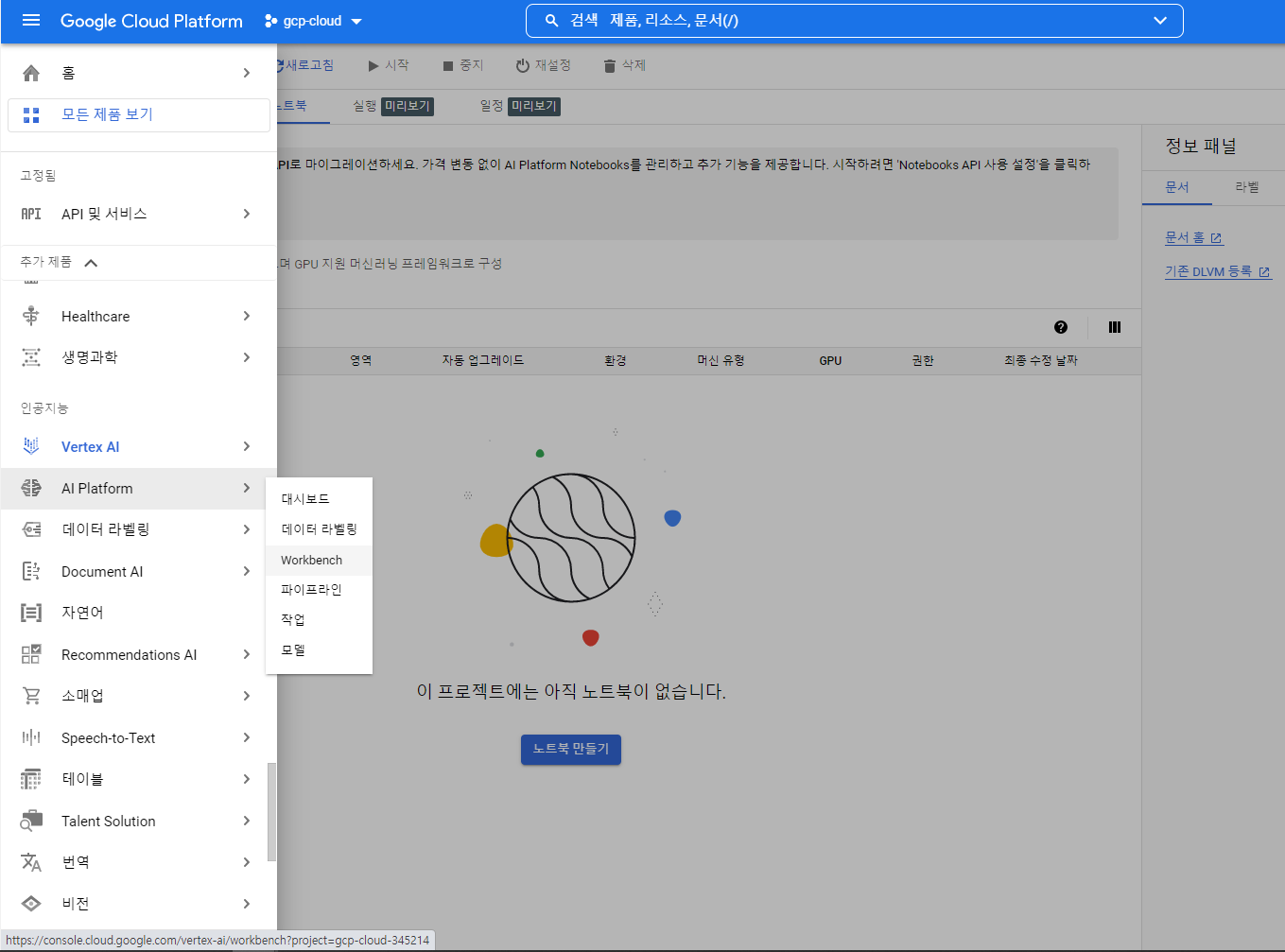
6. 노트북 설정
- server region, CPU, GPU 등을 선택해준다.
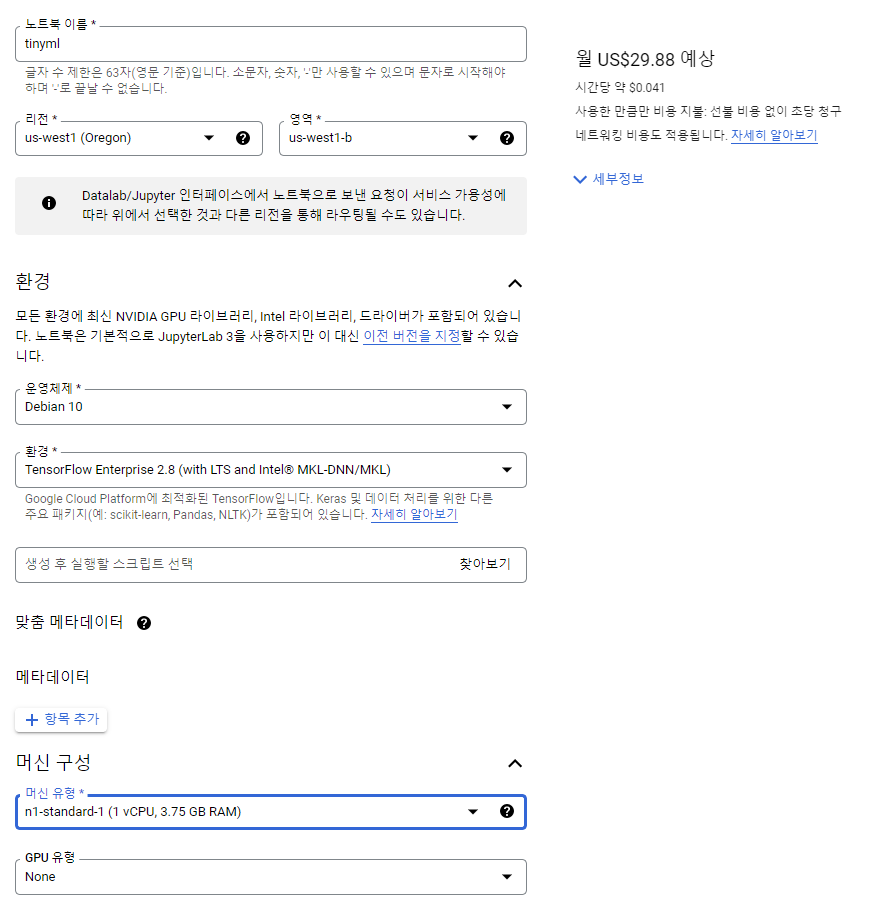
- 가장 낮은 구성으로 선택했는데도 (심지어 GPU 선택도 안함) 몇 만원이 깨진다.
- Notebook 설정은 VM인스턴스와 다르게 무료정책이 없는것 같다 ㅠㅠ
- 아쉽지만 내 고향 Colab으로 돌아가자.. (어째 바뀌는게없어)
Colab 설정 :
- Google Drive 에서 colab notebook을 생성하고 들어가준다 (많이생략)
- gdrive 와 연동해준다.
from google.colab import drive
drive.mount('/content/gdrive')끝. 뭐 선택하고 할게 없으니 간단하다
프레임워크선택 :
Image Classification 모델을 쉽게 사용하는 방법 중 하나인 Tf-Slim을 이용해보자.
Tf-Slim은 텐서플로우 API를 간편하게 사용할 수 있는 고수준 경량 API로 이미지 작업에 대해서는 VGG, Inception, ResNet 등의 모델이 포함되어있으며, pre-trained 모델 기반으로 fine-tuning 과정이 단순화되어있다.
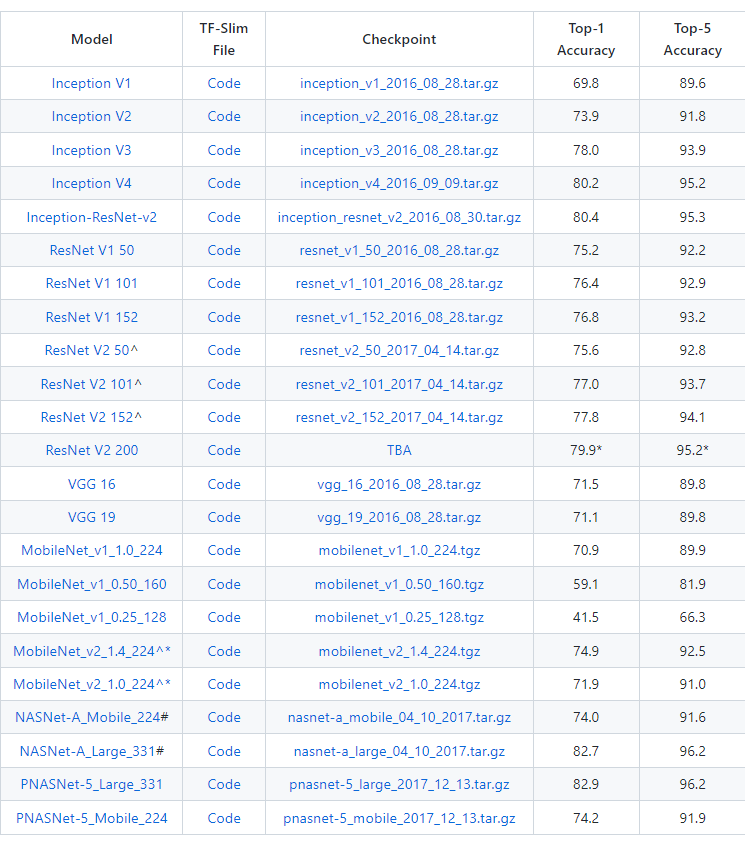
- Slim 모델은 텐서플로 모델 저장소에 있으니 깃헙을 통해 다운받자
! cd ~
! git clone https://github.com/tensorflow/models.git
- 종속성 설치 여부를 확인한다.
! pip install contextlib2
import os
new_python_path = (os.environ.get("PYTHONPATH") or '') + ":models/research/slim"
%env PYTHONPATH=$new_python_path
- export 문 뿐만이 아닌 bash 환경에서 스크립트에 내용을 추가해준다.
! echo 'export PYTHONPATH=$PYTHONPATH:models/research/slim' >> ~/.bashrc
! source ~/.bashrc
데이터셋 구축 :
책에서는 사람 데이터가 있는 COCO 데이터셋을 사용하라고 한다.
사실 사람 인식 이지만 해당 데이터셋의 크기가 너무 커서 label이 5개인 flower classification 데이터로 진행하려 한다.
! python /content/models/research/slim/download_and_convert_data.py --dataset_name=flowers --dataset_dir=data/flowers- 생성된 데이터
tfrecord 파일은 레이블이 부여된 이미지 데이터셋이다.
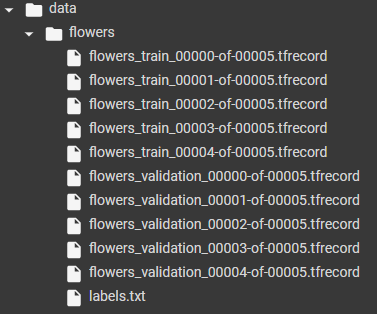
- 라벨은 다음과 같다.
모델 훈련과 평가 :
train_image_classifier.py를 불러와 모델 학습을 해보자.
tensorflow/models/research/slim/train_image_classifier.py
간단하게 파라미터들을 넣어준다.
! python models/research/slim/train_image_classifier.py \
--train_dir=./output/flowers_train_result \
--dataset_name=flowers \
--dataset_split_name=train \
--dataset_dir=./data/flowers \
--model_name=mobilenet_v1 \
--max_number_of_steps=500
이 외에도 아래와 같은 파라미터들이 존재한다.
# --use_grayscale=True \
# --learning_rate=0.045 \
# --label_smoothing=0.1 \
# --learning_rate_decay_factor=0.98 \
# --num_epochs_per_decay=2.5 \
# --moving_average_decay=0.9999 \
# --train_image_size=96
# --batch_size=32 \
# --preprocessing_name=mobilenet_v1 \
# --save_summaries_secs=300 \책에서는 step의 수도 100만으로 잡았지만,, 더 좋은 성능의 GPU로 70시간이 걸렸다고 한다.
위의 파라미터 조정하는 방법은 결국 내가 원하는 방향의 공부는 아니다.
파라미터 조절하는 장인들이 종종 있다고 하는데 물론 재밌지만,, 궁극적으로 모델을 최적화하고 성능을 높이는 방향의 공부를 하고 싶다.
그래서 더이상 위의 파라미터에 대한 설명은 하지 않겠다. 원하신다면 다른 포스팅을 찾아보면 나올겁니다!
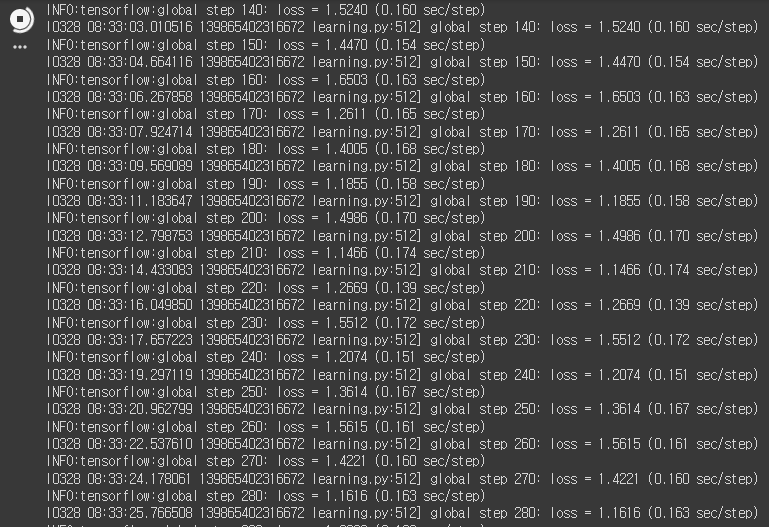
결과는 아래 코드로 확인할 수 있다
! python models/research/slim/eval_image_classifier.py \
--alsologtostderr \
--checkpoint_path=./output/flowers_train_result \
--dataset_dir=./data/flowers \
--dataset_name=flowers \
--dataset_split_name=validation \
--model_name=mobilenet_v1
5개 중에 하나면 찍어도 20%인데 25% 성능이 나오면 의미가 있나?ㅎㅎ
(parameter 최적으로 100만 번 training 시 84%정도 나왔다고 한다 - mobilenet v1 기준)
초반부터 높은 성능을 보려면 pretrained model을 불러와서 사용해도 된다.
$ CHECKPOINT_DIR=/tmp/my_checkpoints
$ mkdir ${CHECKPOINT_DIR}
$ wget http://download.tensorflow.org/models/inception_v3_2016_08_28.tar.gz
$ tar -xvf inception_v3_2016_08_28.tar.gz
$ mv inception_v3.ckpt ${CHECKPOINT_DIR}
$ rm inception_v3_2016_08_28.tar.gz위 코드는 inception_v3 ImageNet1000 pre-trained model 이다.
적절히 5class를 나타내도록 fine tuning 해서 사용하면 된다.
여기서는 아래와 같은식으로 학습 코드를 변경해주면 될것이다.
$ DATASET_DIR=/tmp/flowers
$ TRAIN_DIR=/tmp/flowers-models/inception_v3
$ CHECKPOINT_PATH=/tmp/my_checkpoints/inception_v3.ckpt
$ python train_image_classifier.py \
--train_dir=${TRAIN_DIR} \
--dataset_dir=${DATASET_DIR} \
--dataset_name=flowers \
--dataset_split_name=train \
--model_name=inception_v3 \
--checkpoint_path=${CHECKPOINT_PATH} \
--checkpoint_exclude_scopes=InceptionV3/Logits,InceptionV3/AuxLogits \
--trainable_scopes=InceptionV3/Logits,InceptionV3/AuxLogits \
텐서플로 라이트 :
모델을 임베디드 기기에서 실행할 수 있는 형태로 변환해주기 위함이다.
여기서는 tf_slim을 기준으로 한다.
- GraphDef 프로토콜 버퍼 파일로 모델을 내보내기 (공통형식이기 때문에)
! python models/research/slim/export_inference_graph.py \
--alsologtostderr \
--dataset_name=flowers \
--model_name=mobilenet_v1 \
--output_file=flower_graph.pb
- 가중치 고정하기 (모델과 값을 함께 저장하는 작업)
! git clone https://github.com/tensorflow/Tensorflow
! python tensorflow/tensorflow/python/tools/freeze_graph.py \
--input_graph=flower_graph.pb \
--input_checkpoint=output/flowers_train_result/checkpoint \
--input_binary=true \
--output_graph=flower_frozen.pb \
--output_node_names =MobilenetV1/Predictions/Reshape_1고정된 값의 pb 파일이 생성되었다.
- 양자화와 tf lite 변환
훈련된 부동소수점 그래프를 8bit로 양자화 하는 코드이다.
완료 시 tf lite FlatBuffer 파일이 생성된다.
import tensorflow as tf
import io
import PIL
import numpy as np
def representative_dataset_gen():
recore_iterator = tf.python_io.tf_record_iterator(path='data/flowers')
count = 0
for string_record in record_iterator:
example = tf.train.Example()
example.ParseFromString(string_record)
image_stream = io.BytesIO(example.features.feature['image/encoded'].bytes_list.value[0])
image = PIL.Image.open(image_stream)
image = image.resize((96,96))
image = image.convert('L')
array = np.array(image)
array = np.expand_dims(array, axis=2)
array = np.expand_dims(array, axis=0)
array = ((array/127.5)-1.0).astype(np.float32)
yield([array])
count += 1
if count >300 :
break
converter = tf.lite.TFLiteConverter.from_frozen_graph \
('flower_frozen.pb',['input'],['MobilenetV1/Predictions/Reshape_1'])
converter.inference_input_type = tf.lite.constants.INT8
converter.inverence_output_type = tf.lite.constants.INT8
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_dataset_gen
tflite_quant_model = converter.convert()
open("flower_quantized.tflite", "wb").write(tflite_quant_model)
- C source file로 변환
모두 마치면 tflite 파일로 결과물이 나오지만, 임베디드 기기에는 파일시스템이랄게 없기 때문에 실행파일로 컴파일하여 직렬화된 데이터로 변환하여 저장해야된다.
! apt-get -qq install xxd
! xxd -i flower_quantizexd.tflite > person_detect_model_data.cc
마무리하며 :
쭉 따라서 공부를 해보니 굳이 tf slim을 쓸 필요가 없었던 것 같다.
slim만 가지고 있는 장점이 있는줄 알았더니 그건 아니였고 괜히 tf version 만 1.15로 바꾸느라 귀찮았다.
1. keras건 뭐건 쉽게 작업할 수 있는 API나,
2. 더 좋은 모델을 제공하는 API,
3. 직접 만든 모델로도
tflite -> c로 변환을 할 수 있으니 tf_slim에 묶여있지 않아도 될것 같다.
이번 장에서 얻을 수 있던 건 모델을 내가 학습시켜서 올릴수도 있다는거!
그 과정에서 성능을 높이기 위해서는
API - 파라미터 조정 등 skill / 모듈단위로 수학적 최적화
끝
'공부 > ML&DL' 카테고리의 다른 글
| [머신러닝 공부] Tiny ML -18 / 제스처인식 어플리케이션 -2 (0) | 2022.04.16 |
|---|---|
| [머신러닝 공부] Tiny ML -17 / 제스처인식 어플리케이션 -1 (0) | 2022.04.02 |
| [머신러닝 공부] Tiny ML -15 / 인체감지 어플리케이션-3 (2) | 2022.03.22 |
| [머신러닝 공부] Tiny ML -14 / 인체감지 어플리케이션-2 (2) | 2022.02.26 |
| [머신러닝 공부] Tiny ML -13 / 인체감지 어플리케이션-1 (0) | 2022.02.17 |


