
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- 삼성역량테스트
- sort
- 포스코 AI교육
- 포스코 교육
- bfs문제
- 코테
- BFS
- 삼성역테
- MCU 딥러닝
- DP문제
- tflite
- DP
- 다이나믹프로그래밍
- 영상처리
- 삼성코딩테스트
- 초소형머신러닝
- 포스코 ai 교육
- 알고리즘
- 코테 문제
- dfs문제
- 컴퓨팅사고
- 임베디드 딥러닝
- dfs
- tinyml
- 자료구조
- 딥러닝
- 그리디
- 코딩테스트
- 삼성코테
- TensorFlow Lite
- Today
- Total
코딩뚠뚠
[머신러닝 공부] 딥러닝/앙상블(ensemble) 본문
앙상블 포스팅 계기 :
앙상블 기법의 존재여부도 최근에야 알게됐다.
AI 공모전에 참여하며 우수자들이 ensemble을 사용하는 것을 보고 공부를시작했고, Fast campus 머신러닝과정에서 ensemble에 대한 강의도 듣게 되며 포스팅까지 하게 됐다.
또한 Tree를 주로 사용하는 머신러닝기법이 아닌 딥러닝 모델을 사용해, Image Classification에서 앙상블을 적용시켜보고 싶었다.
목차 :
1.
[머신러닝]
앙상블에 대한 기초적인 개념과 종류, Bagging, RandomForest, Boosting, Stacking 등에 대해 알아본다.
2.
[딥러닝]
ResNet50을 앙상블 하여 Classification 성능을 높여본다.
1. (ML) 앙상블 개념 및 기법들
앙상블이란 :
- 사전적의미 : 연주나 연극 등의 통일적 효과나 조화. 순화어는 `조화'.
사전적의미와 같이 '조화' 하는것이다. 무엇을? 모델을
여러 모델의 결과를 모아 최종 결과를 내어 성능을 향상시키는 기법이다.
아래의 예시 그림을 보면 이해하기 편하다.

특징 :
- 대부분은 ensemble 사용시 정확도가 높아진다.
- 각 모델별 특징이 두드러지는 즉 over fitting이 잘 되는 모델을 기본적으로 사용한다. (ML에선 Tree기반 모델 사용)
기법 종류 :
- Bagging - 모델의 다양화를 위해 데이터를 재구성
- RandomForest - 모델의 다양화를 위해 데이터와 변수를 재구성
- Boosting - 맞추기 어려운 데이터에 대해 가중치를 두어 학습
+ Stacking - 모델의 output값을 새로운 독립변수로 이용
1. Bagging
전체 데이터 중 일부를 추출(복원추출)해서 이를 Tree를 통한 예측을 실시한다.
여러 Tree를 거친 prediction을 모아 최종 prediction을 도출한다.

전체 데이터의 약 63% 정도만 추출되고 미 추출된 데이터로는 Error를 계산할 수 있다. (OOB error)
깊이 성장한 Tree는 overfitting 을 증가시키고 / 분산이 증가 / 편향이 감소한다.
Bagging을 통해서는 편향을 유지하면서 / 분산을 낮출 수 있게 되어 noise에 강해지게 된다.
2. RandomForest
Bagging의 분산은 각 트리들의 분산과 그들의 공분산으로 이루어져 있다.
ex) Var(X+Y) = Var(X) + Var(Y) + 2Cov(X,Y)
복원추출을 진행했으나 각 트리들은 중복데이터를 가지고 있기 때문에 독립이라는 보장이 없다.
공분산이 0이 아님에 따라 Tree가 증가하면 모델 전체의 분산이 증가할 수 있다.
따라서 각 트리간 공분산을 줄일 수 있는 방법인 RandomForest 방법이 대두
즉 DB뿐 아닌 변수까지 랜덤으로 뽑는 컨셉으로 base learner 간 공분산을 줄이자는 것
아래 사진을 보면 위의 Bagging 사진과 다르게 변수까지 같이 뽑은것을 볼 수 있다.

일반적으로 Bagging 기법보다 성능이 좋다고 한다.
3. Boosting
맞추기 힘든 데이터에 가중치를 두어 학습하는 방법이다.
즉 오분류 된 데이터에 초점을 맞춘다. -> 다음 Round 에서 더 많이 수정되게 된다.
종류 : AdaBoost, Gradient Boosting, XGBoost, LightGBM, Catboost 등
Boosting 종류간 차이는 오분류된 데이터를 다음 Roung에 어떻게 반영할 것인가의 차이이다.

Boosting 기법들을 정리해 놓은 블로그가 있어 링크를 가져와봤다.
jinsu-l.github.io/machinelearing/BOOSTING/?
4. Stacking
Meta Learner 라고 불리며, 다양한 모델들을 사용하는 특징이 있다.
x Fold cross validation이 필요하며 학습 시간이 오래 걸린다.
x = 5 라고 두었을 때 학습데이터와 검증데이터가 나뉠 것이다.
이에 대해 총 4개의 모델로 예측결과를 도출하고 이 결과와 기존 데이터를 합한 것이 새로운 검증 데이터가 되게 된다.
좋은 GIF 이미지가 있어 블로그 주소와 함께 첨부한다.
3months.tistory.com/192
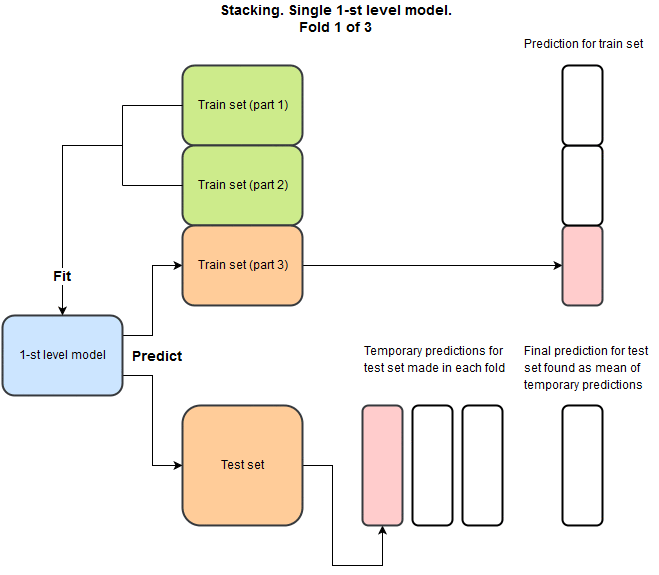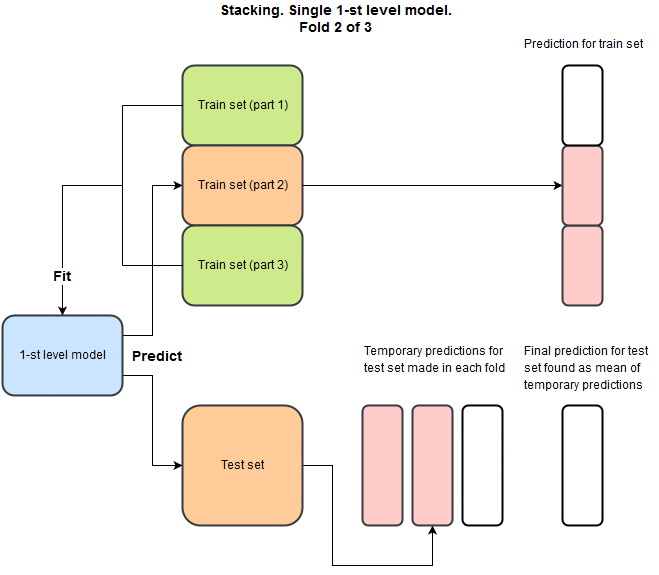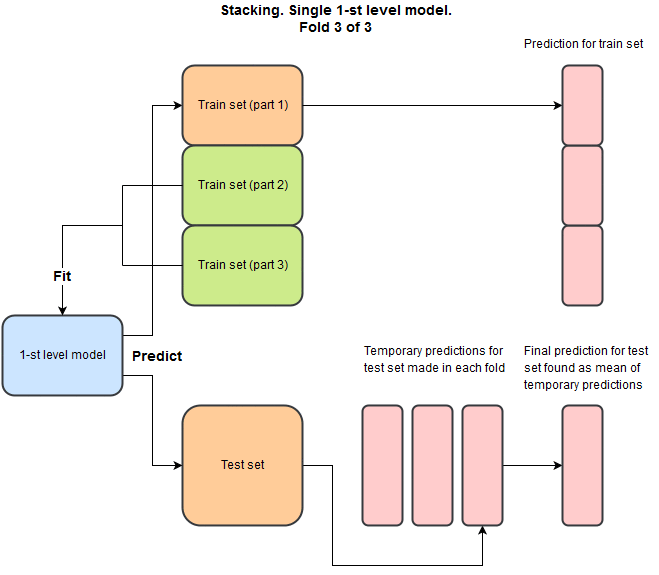
기법에 대한 설명은 여기까지이다.
2. (DL) 앙상블 사용
딥러닝 성능을 향상하기 위한 기법으로 사용할 수 있다.
각각 다른 신경망으로 학습데이터에 대해 각각 따로 학습을 시킨 후, n개의 예측값을 출력시키고 그것을 n으로 나눈 평균값을 최종 출력으로 하는 것이다. (Stacking사용)
오버피팅의 해결과 약간의 정확도 상승 효과가 실험을 통해 입증되었다.
또한 평균이 아닌 투표방식, weight별 가중치를 다르게 주는 방법들도 존재한다.
ex) pretrained 된 모델들을 앙상블모델로 만들어 분류의 성능을 높이자
- DataLoader 생성
- 모델1, 모델2, 모델3 생성 (ResNet, Inception, DensNet 예시)
- 각 모델에서 컨볼루션 feature 추출
- 그 feature들로 학습, 검증 데이터셋 생성 및 DataLodaer 생성
- 앙상블 모델 생성
- 앙상블 모델 학습
ex) 각 모델의 prediction값을 평균낸 결과를 최종 결과로 사용하자
1. DataLoader 생성
2. 모델1, 모델2, 모델3 생성 및 각각 학습
3. 세 가지 모델 모두 앙상블로 결합 (모델이 인스턴스화 되고 가장 좋은 가중치가 로드된다.)
conv_pool_cnn_model = conv_pool_cnn(model_input) all_cnn_model = all_cnn(model_input) nin_cnn_model = nin_cnn(model_input) conv_pool_cnn_model.load_weights('weights/conv_pool_cnn.29-0.10.hdf5') all_cnn_model.load_weights('weights/all_cnn.30-0.08.hdf5') nin_cnn_model.load_weights('weights/nin_cnn.30-0.93.hdf5') models = [conv_pool_cnn_model, all_cnn_model, nin_cnn_model]4. 그저 평균을 내주는 ensemble 모델을 만든다.
def ensemble(models, model_input): outputs = [model.outputs[0] for model in models] y = Average()(outputs) model = Model(model_input, y, name='ensemble') return model ensemble_model = ensemble(models, model_input)
이와 같이 여러 방법으로 딥러닝을 이용한 image classification, object detection 등에서 앙상블 기법을 적용할 수 있다.
References
관련 영상 주소 : www.youtube.com/watch?v=b4x4roTt5QM&t=388s
관련 깃헙 주소1 : github.com/digitalbrain79/resnet-ensemble
관련 깃헙 주소2 : github.com/KerasKorea/KEKOxTutorial/blob/master/16_Ensembling%20ConvNets%20using%20Keras.md
'공부 > ML&DL' 카테고리의 다른 글
| [머신러닝 공부]딥러닝/Optimizer정리 (5) | 2021.07.18 |
|---|---|
| [머신러닝 공부] 딥러닝/Activation Function종류 (0) | 2021.07.11 |
| [머신러닝 공부] 딥러닝/SSD (object detection) (0) | 2021.04.27 |
| [머신러닝 공부] 딥러닝/YOLO V1 (object detection) (0) | 2021.04.21 |
| [머신러닝 공부] K-Fold Cross Validation 이란 (0) | 2021.04.18 |



