
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- bfs문제
- 알고리즘
- 삼성코테
- DP
- tinyml
- DP문제
- 딥러닝
- 임베디드 딥러닝
- MCU 딥러닝
- 삼성코딩테스트
- sort
- 컴퓨팅사고
- 삼성역테
- dfs문제
- BFS
- 다이나믹프로그래밍
- 코테
- 삼성역량테스트
- 코테 문제
- 초소형머신러닝
- 자료구조
- 그리디
- 코딩테스트
- 포스코 AI교육
- 포스코 교육
- 영상처리
- tflite
- dfs
- 포스코 ai 교육
- TensorFlow Lite
- Today
- Total
코딩뚠뚠
[머신러닝 공부]딥러닝/Optimizer정리 본문
이번 포스팅에서는 딥러닝에 이용되는 Optimizer=최적화알고리즘 을 알아보고자 한다.
'어떤 Optimizer를 써야되는지 잘 모르겠다면 Adam을 써라'
라는 말이 있다.
왜 그냥 Adam을 쓰라고 했을까?
Optimization 의 큰 틀부터 보자
딥러닝의 학습에서는 최대한 틀리지 않는 방향으로 학습해 나가야 한다.
여기서 얼마나 틀리는지(loss)를 알게 하는 함수가 loss function=손실함수이다.
loss function의 최소값을 찾는 것을 학습의 목표로 한다.
여기서 최소값을 찾아가는 것을 최적화=Optimization 이라고 하고
이를 수행하는 알고리즘이 최적화 알고리즘=Optimizer 이다.
Optimizer 종류
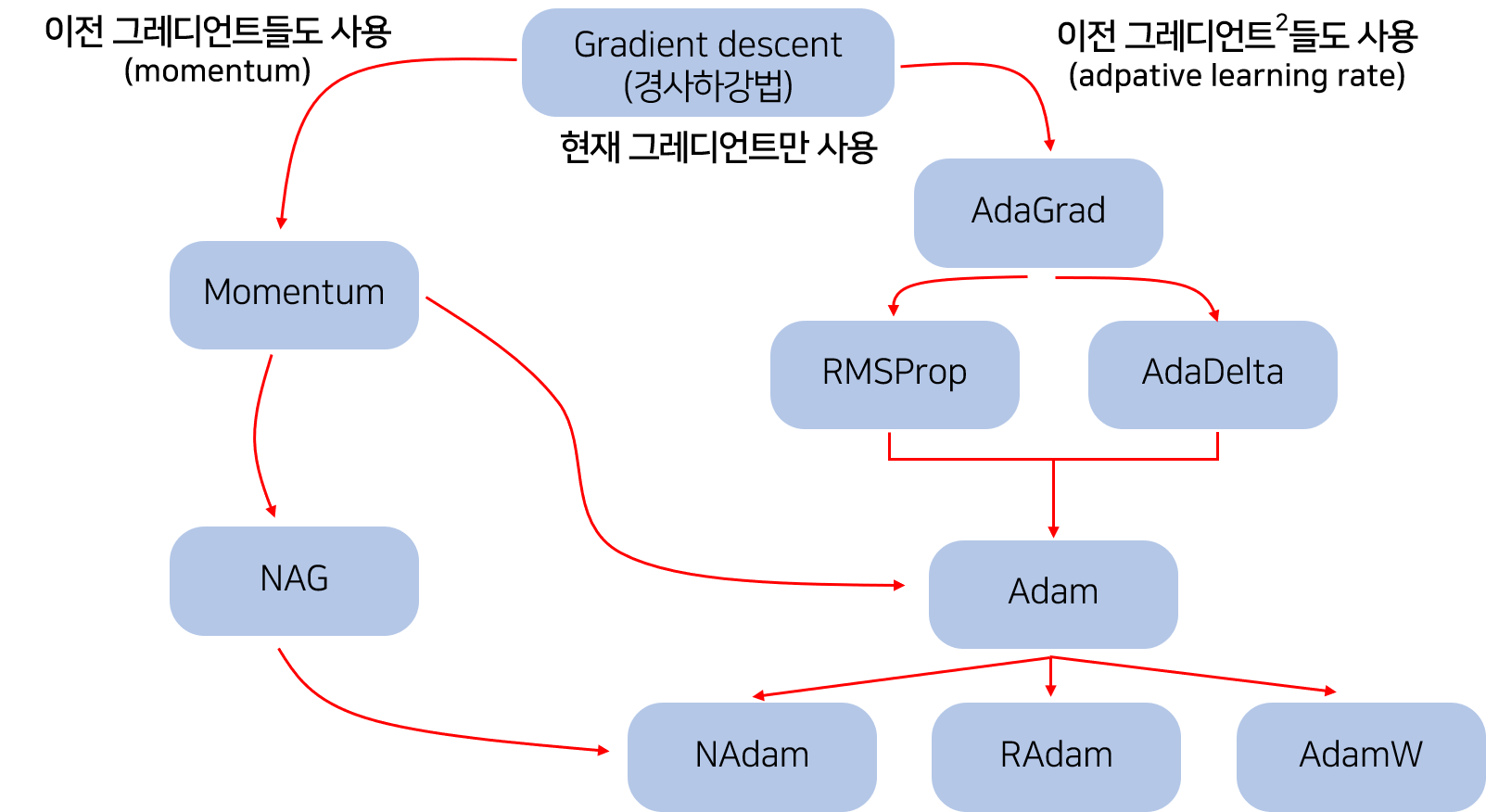
0. Gradient Descent (경사하강법)
이후의 Optimizer 도 Gradient Descent의 종류들이지만 vanilla gradient descent 부터 시작하려 한다.
Gradient descent 의 업데이트 수식은 아래와 같다.
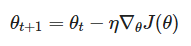
n : learning rate
J(θ) : 목적함수, 여기서는 loss function
Batch Gradient Descent
기본적인 gradient descent 알고리즘은 batch gradient descent 를 말한다.
파라미터 업데이트를 위해 데이터 전체를 계산에 이용하는 것이며 속도가 느린 단점이 있다.
Stochastic Gradient Descent
SGD라고 줄여부른다.
하나의 훈련데이터만 계산에 이용해서 속도가 빠르다는 장점이 있다.
하지만 일정하지 않은 gradient로 파라미터를 업데이트하는 것은 수렴을 방해할 수 있다.
Mini-batch Gradient Descent
딥러닝을 처음 접할때 batch_size=32 와 같이 설정해 주곤 한다. 이것이 mini-batch를 이용하는 것이다.
설정해 준 mini-batch 만큼의 훈련데이터를 목적함수의 계산에 이용한다.
1. Momentum
관련논문 : https://arxiv.org/abs/1609.04747
An overview of gradient descent optimization algorithms
Gradient descent optimization algorithms, while increasingly popular, are often used as black-box optimizers, as practical explanations of their strengths and weaknesses are hard to come by. This article aims to provide the reader with intuitions with rega
arxiv.org

파라미터 업데이트 시 local minimum 에 빠지게 될 수 있다.
따라서 이전 gradient들도 계산에 포함해서 현재 파라미터를 업데이트 해준다.
즉 gradient가 0이 되게 놔두지 않는다.
하지만 이전 gradient들을 모두 동일한 비율로 포함시키지는 않고 비율을 감소시켜준다.
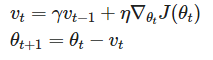
2. Adagrad
논문 : https://arxiv.org/abs/1609.04747
An overview of gradient descent optimization algorithms
Gradient descent optimization algorithms, while increasingly popular, are often used as black-box optimizers, as practical explanations of their strengths and weaknesses are hard to come by. This article aims to provide the reader with intuitions with rega
arxiv.org
앞에서의 SGD 와 모멘텀은 모든 파라미터에 같은 lr을 적용한다는 것이다.
하지만 수렴지점으로 빨리 나아가기 위해서는 파라미터의 업데이트 빈도 수에 따라 업데이트 정도 lr을 다르게 해줘야 할 필요가 있다.
따라서 Ada(Adaptive) 라는게 등장하는데 이는 '상황에 맞게 변화하는' 이라는 뜻을 가진다.
Adagrad가 위에서의 문제를 해결하는 방법
- 업데이트 정도를 알기 위해 Adagrad 는 이전의 gradient를 저장한다.
- 업데이트 시 아래와 같이 분모에 루트를 씌운 식을 사용한다.

- 업데이트 빈도 수가 높은 파라미터는 분모에 의해 n(lr)보다 작게 업데이트 된다.
하지만 t가 증가함에 따라 Gt,i 값이 커지게 되어 lr이 소실되는 문제점이 있다.
3. Adadelta
논문 : https://arxiv.org/abs/1212.5701
ADADELTA: An Adaptive Learning Rate Method
We present a novel per-dimension learning rate method for gradient descent called ADADELTA. The method dynamically adapts over time using only first order information and has minimal computational overhead beyond vanilla stochastic gradient descent. The me
arxiv.org
Adagrad 의 lr 소실문제를 해결하기 위해 나온 알고리즘
이를 위해 이전의 모든 gradient 정보를 저장하지 않고 지난 x개의 gradient 정보만을 저장한다.
+ 과거의 gradient정보의 영향력을 감소시키기 위해 decaying average of squared gradient 식을 사용

4. RMSProp
논문 : https://arxiv.org/abs/1609.04747
An overview of gradient descent optimization algorithms
Gradient descent optimization algorithms, while increasingly popular, are often used as black-box optimizers, as practical explanations of their strengths and weaknesses are hard to come by. This article aims to provide the reader with intuitions with rega
arxiv.org
RMSProp은 Adadelta와 마찬가지로 Adagrad의 lr 소실 문제를 해결하기 위해 개발된 알고리즘이다.
update 식은 Adadelta와 같으나 γ 값으로 0.9를, η값으로 0.001을 제안한 알고리즘

5. Adam (Adaptive Moment Estimation)
논문 : https://arxiv.org/abs/1412.6980
Adam: A Method for Stochastic Optimization
We introduce Adam, an algorithm for first-order gradient-based optimization of stochastic objective functions, based on adaptive estimates of lower-order moments. The method is straightforward to implement, is computationally efficient, has little memory r
arxiv.org

현재 가장 많이 사용되는 옵티마이저이다.
각 파라미터마다 다른 크기의 업데이트를 적용하는 방법으로 앞의 Adagrad, Adadelta, RMSProp과 유사하다고도 할 수 있다.
(한줄로 설명하는 분들은 RMSProp과 Momentum 두가지를 섞어 쓴 알고리즘이라 설명한다.)
Adadelta에서의 decaying average of squared gradient와 추가적으로 decaying average of gradient를 사용했다.
즉
업데이트 식은 다음과 같다.

이외에도 설명하지 않은 NAG, AdaMax, NAdam, AdamW 등도 존재한다.
공부하고 상황에 맞게 쓰면된다..(말은쉽다)
아래는 Optimizer를 쉽게 설명해 놓은 사진을 가져와 봤다.
(너무 널리 퍼져있는 자료여서 출처를 명확히 모르겠다..)

'공부 > ML&DL' 카테고리의 다른 글
| [머신러닝 공부] Tiny ML -2 / 서론,시작하기 (0) | 2021.10.27 |
|---|---|
| [머신러닝 공부] Tiny ML -1 / 개요 (0) | 2021.09.22 |
| [머신러닝 공부] 딥러닝/Activation Function종류 (0) | 2021.07.11 |
| [머신러닝 공부] 딥러닝/앙상블(ensemble) (0) | 2021.05.03 |
| [머신러닝 공부] 딥러닝/SSD (object detection) (0) | 2021.04.27 |



