
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
Tags
- 포스코 AI교육
- dfs문제
- 코테 문제
- TensorFlow Lite
- DP문제
- 영상처리
- 포스코 교육
- 컴퓨팅사고
- 삼성코테
- tinyml
- sort
- 코딩테스트
- 알고리즘
- BFS
- MCU 딥러닝
- 삼성역량테스트
- 임베디드 딥러닝
- 자료구조
- dfs
- 딥러닝
- 다이나믹프로그래밍
- 코테
- 초소형머신러닝
- 그리디
- bfs문제
- 삼성코딩테스트
- 삼성역테
- tflite
- DP
- 포스코 ai 교육
Archives
- Today
- Total
코딩뚠뚠
[머신러닝 공부] Tiny ML -4 / 모델 구축과 훈련 본문
반응형
Chapter4. 모델 구축과 훈련
"
이번 챕터에서는 모델을 처음부터 빌드하고 훈련시킨 후 간단한 마이크로컨트롤러 프로그램에 통합해본다.
"
4장의 목차는 아래와 같다
- 간단한 데이터셋 얻기
- 딥러닝 모델 훈련시키기
- 모델 성능 평가하기
- 장치에서 실행되도록 모델 변환하기
- 장치에서 추론하는 코드 작성하기
- 코드를 바이너리로 빌드하기
- 바이너리를 마이크로컨트롤러에 배포하기
- 이번장에서는 사인파 데이터를 훈련시킬 것이다.
x 값이 들어왔을 때 사인함수의 결과인 y를 예측하할 수 있는 모델을 학습시키려는 것이다.
현재 내 환경은 GPU성능이 낮은 노트북이기 때문에 Colab에서 실행했다.
import tensorflow as tf import numpy as np import matplotlib.pyplot as plt import math
- 필요한 패키지들을 import 한다.
- tensorflow, 수학연산을 하기 위한 math와 numpy, 그래프를 그리기 위한 matplotlib
데이터 생성
SAMPLES = 1000 np.random.seed(아무숫자나) x_values = np.random.uniform(low=0, high=2*math.pi, size=SAMPLES) np.random.shuffle(x_values) y_values = np.sin(x_values) plt.plot(x_values, y_values, 'b.') plt.show()- 데이터 샘플을 1000개 생성한다
- 실행할때마다 다른 랜덤 값을 얻게끔 해준다
- x_values : 사인파 진폭의 범위인 2π 내에서 균일분포된 난수 집합을 생성한다.
- y_values : sin함수로 사인값을 계산한다.
- plt으로 데이터를 그래프로 그린다. 'b' 인수로 점을 파란색으로 출력하도록 한다.

노이즈추가
y_values += 0.1 * np.random.randn(*y_values.shape) plt.plot(x_values, y_values, 'b.') plt.show()- 각 y값에 숫자를 랜덤으로 추가해준 후 그래프를 생성해주어 실제 데이터와 비슷하게 만들어준다.
데이터 분할
TRAIN_SPLIT = int(0.6 * SAMPLES) TEST_SPLIT = int(0.2 * SAMPLES + TRAIN_SPLIT) x_train, x_test, x_validate = np.split(x_values, [TRAIN_SPLIT, TEST_SPLIT]) y_train, y_test, y_validate = np.split(y_values, [TRAIN_SPLIT, TEST_SPLIT]) assert (x_train.size + x_validate.size + x_test.size) == SAMPLES plt.plot(x_train, y_train, 'b.', label="Train") plt.plot(x_test, y_test, 'r.', label="Test") plt.plot(x_validate, y_validate, 'y.', label="Validate") plt.legend() plt.show()- train / test / validation 을 6:2:2로 나눠준다.
- 각 데이터들을 다른 색상으로 그래프에 표시해준다.

모델 설계
from tensorflow.keras import layers model_1 = tf.keras.Sequential() model_1.add(layers.Dense(16, activation='relu', input_shape=(1,))) model_1.add(layers.Dense(1)) model_1.compile(optimizer='rmsprop', loss='mse', metrics=['mae'])- 케라스를 이용해 매우 간단한 모델을 설계한다
모델 훈련
history_1 = model_1.fit(x_train, y_train, epochs=1000, batch_size=16, validation_data=(x_validate, y_validate))
훈련지표 확인
loss = history_1.history['loss'] val_loss = history_1.history['val_loss'] epochs = range(1, len(loss) + 1) plt.plot(epochs, loss, 'g.', label='Training loss') plt.plot(epochs, val_loss, 'b', label='Validation loss') plt.title('Training and validation loss') plt.xlabel('Epochs') plt.ylabel('Loss') plt.legend() plt.show()- Epoch에 따른 Training Loss와 Validation Loss를 나타낸다.
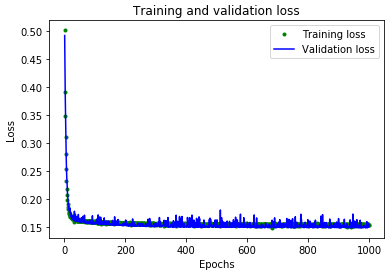
책에는 이외에도 추가지표를 활용하여 모델을 평가하고 새로운 모델을 만들기도 한다.
하지만 비슷한 과정이므로 다음과정으로 넘어간다.
Tensorflow Lite로 변환
#양자화없이 Lite로 변환 converter = tf.lite.TFLiteConverter.from_keras_model(model_2) tflite_model = converter.convert() open("sine_model.tflite", "wb").write(tflite_model) #양자화해서 Lite로 변환 converter = tf.lite.TFLiteConverter.from_keras_model(model_2) converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE] tflite_model = converter.convert() open("sine_model_quantized.tflite", "wb").write(tflite_model)- Tensorflow Lite Converter를 사용해서 변환한다.
- 양자화 (quantization)를 사용해서 모델의 정밀도를 낮추지만 정확도에 큰 영향을 미치지 않으면서 메모리를 절약과 실행속도도 빨라진다.
모델 테스트
- 모델이 양자화 변환 후에도 정확한지 보기 위해 테스트 한다.

- 모델 크기 차이도 확인할 수 있다.

C파일에 쓰기
!apt-get -qq install xxd !xxd -i sine_model_quantized.tflite > sine_model_quantized.cc !cat sine_model_quantized.cc- C 소스파일로 변환하는 단계이다.
- xxd를 사용한다.
unsigned char sine_model_quantized_tflite[]=
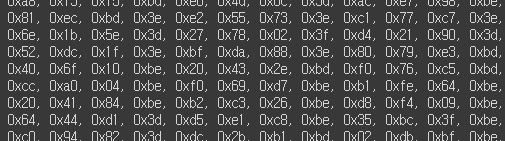
- 위와 같은 형식으로 변환되었다.
이 모델을 프로젝트에서 사용하려면 소스를 복붙하거나 파일을 다운로드하면 된다.
모델 구축과 훈련을 진행해 보았고, 다음장에서는 애플리케이션을 구축해볼 것이다.
출처 : https://github.com/tinyml-mobility/tensorflow-lite
GitHub - tinyml-mobility/tensorflow-lite: <TinyML: 텐서플로우 라이트> 소스코드 저장소
<TinyML: 텐서플로우 라이트> 소스코드 저장소 . Contribute to tinyml-mobility/tensorflow-lite development by creating an account on GitHub.
github.com
끝
반응형
'공부 > ML&DL' 카테고리의 다른 글
| [머신러닝 공부] Tiny ML -6 / 어플리케이션 구축-2 (0) | 2021.12.21 |
|---|---|
| [머신러닝 공부] Tiny ML -5 / 어플리케이션 구축-1 (0) | 2021.12.08 |
| [머신러닝 공부] Tiny ML -3 / 머신러닝 빠르게 훑어보기 (0) | 2021.11.01 |
| [머신러닝 공부] Tiny ML -2 / 서론,시작하기 (0) | 2021.10.27 |
| [머신러닝 공부] Tiny ML -1 / 개요 (0) | 2021.09.22 |
'공부/ML&DL' Related Articles
more



