
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- sort
- 삼성역량테스트
- DP
- tflite
- 코테
- 코테 문제
- 포스코 ai 교육
- 그리디
- 포스코 교육
- 영상처리
- bfs문제
- 자료구조
- MCU 딥러닝
- 삼성코딩테스트
- 코딩테스트
- 다이나믹프로그래밍
- dfs
- 포스코 AI교육
- BFS
- 삼성코테
- 초소형머신러닝
- 삼성역테
- tinyml
- TensorFlow Lite
- 임베디드 딥러닝
- 컴퓨팅사고
- DP문제
- 알고리즘
- dfs문제
- 딥러닝
- Today
- Total
코딩뚠뚠
[대학활동] 2020 캡스톤디자인 2 프로젝트 본문
4학년 2학기에 수강한 캡스톤디자인2 과목
과목 소개 :
캡스톤디자인 말의 의미 :
Capstone - 건축물 맨 위에 올려놓는 관석 으로 가장 아름답다고 한다. (대학의 마무리를 짓는 의미)
Capstone Design 은 학생들이 대학에서 배운 이론을 바탕으로 작품을만드는 프로젝트이다.
3년간 학교에서 배운 지식을 활용하여 산업체,사회 가 필요로 하는 과제를 대상으로 프로젝트를 진행
주제 :
"SoC기반 머신러닝을 이용한 숫자인식 모델 설계"
캡스톤디자인1 프로젝트 시 네트워크를 이용하여 API의 결과를 받아오게 되어 시간이 딜레이 되었었다.
이에 인공지능에 사용되는 머신러닝 네트워크를 하드웨어언어로 구현하면 어느정도의 속도향상이 있는지 연구하는 프로젝트이다.
즉 하드웨어 병렬연산을 통해 기존 연산의 가속을 목표로 하였다.
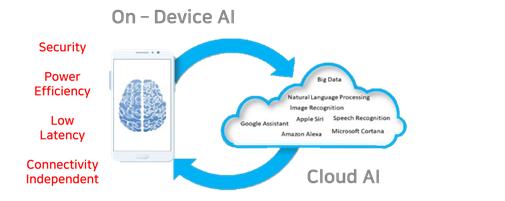
On device AI 의 시작으로도 볼 수 있을것이다.
- 네트워크가 없는 환경에서도 사용가능
- 속도에의 장점
- 보안에의 장점
- 저전력
준비 :
1. 아이디어 창출 (브레인스토밍)
끄적였다.
FPGA를 사용하는 연산이 ARM 프로세서보다 빠른것을 어떻게 증명할 것인지
그 개념에 대해서 공부하고 회의했다.
그리고 활용방안에 대해 생각했다.
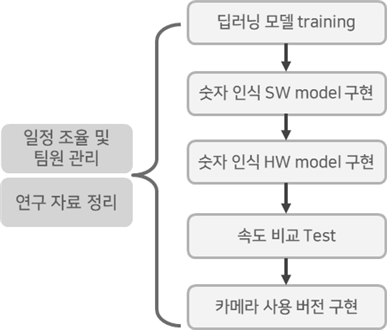
2. 수행체계도
3. 사용 장비

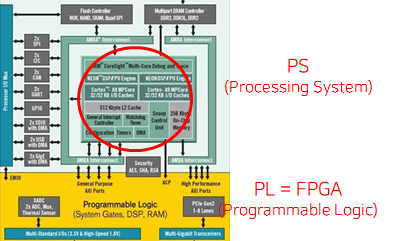
Main process 는 Zedboard Zynq-7000 으로 진행하였다.

카메라를 이용한 응용방안으로는 DE1-SoC Board와 D5M Camera를 이용하였다.
4. 연구 목표
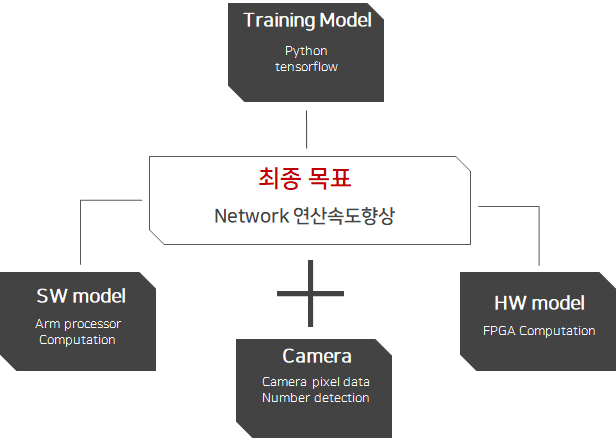
수행 및 결과 :
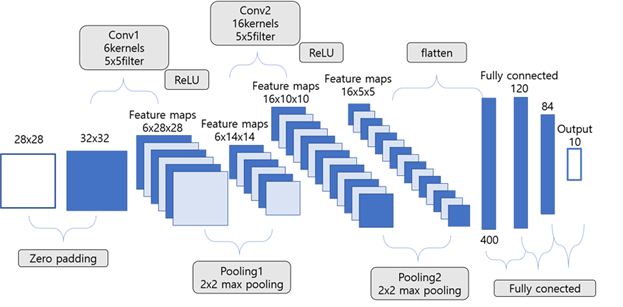
최종적으로 이와같은 모델을 구축할 수 있었다.
[설계환경 : Pycharm (python-tensorflow) ]
숫자를 인식하는 것이기에 복잡한 과정은 필요치 않았고 보드의 캐시메모리를 적게 쓰기 위해 간단하게 구성하였다.
MNIST test data 로 구축된 모델을 평가했을 때 정확도는 98.99%로 도출되었다.
Training 이후 이 모델을 그대로 C언어로 구현하기 위해 weight와 bias를 추출하는 과정을 거쳤다.

이후 python으로 작성한 Network를 C언어로 변환하는 과정을 거쳤다.
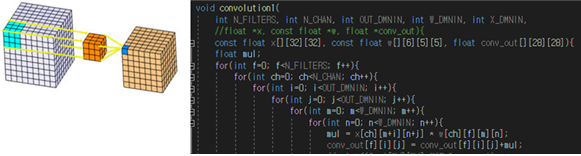
위 사진은 convolution을 C언어로 재구성한 코드의 예시이다.
이외에도 ReLU, Pooling, flatten, fully connected 과정들을 C코드로 바꾸어주었다.
이렇게 변경된 C 코드는 PS단 즉 ARM 부분에서 동작을 가능하게 하였다.
정확도 테스트 결과 48/50 = 96%의 정확도를 보였고 추론모델의 동작시간은 253ms 로 측정되었다.
약간의 오차는 실험 데이터의 부족으로 판단하였다.
이후 C언어로 변환한 모델을 Vivado HLS를 이용하여 Verilog 언어로 합성해주었다.
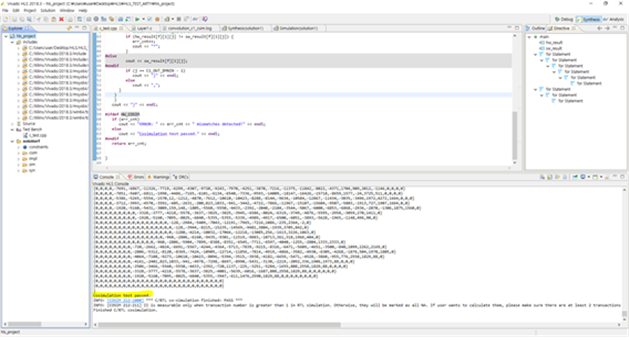
합성한 후에는 cosimulation 코드를 작성하여 이전의 PS모델과 같은지에 대해 증명하는 과정을 수행해주었다.
각각에 동일한 input을 주고 output을 확인함으로써 모델이 완전히 일치함을 증명하였다.
속도측정은 synthesis report를 확인하는 방법으로 측정하였다.
정확도는 PS 부분의 코드와 동일한 96% 임이 증명되었고 속도는 5ms가 도출되었다.

결과적으로 HW 가속기를 통해 연산시간이 98% 감소됨을 알 수 있었다.
이를 이용해 카메라를 통한 응용방안을 구현해보았다.

Quartus 의 Qsys를 이용하여 보드를 setting 하고 Camera의 픽셀 input 을 받아오고 캡쳐가 가능하게 소스코드를 작성했다.
이후 실제 숫자 이미지를 이용해 숫자검출을 테스트 할 수 있었다.

단 영상처리는 없이 그저 응용방안을 제시한 것으로 정확도는 80%로 낮게 측정되었다.
내 역할 :
위의 수행과정에서 python-tensorflow로 초기 머신러닝 Network를 구성하는 것과 이를 C언어로 변환하는 과정
문제점과 해결방안 :
1. 정확도를 높이기 위한 네트워크를 구성했더니 SoC Board로 옮기기 위한 메모리가 부족해 weight와 bias를 한번에 옮기지 못함
-> 정확도가 조금 떨어지더라도 hidden layer를 줄이자. 대신 raw에 padding을 해줌으로써 특징추출을 더 많이 하게만들어 layer를 줄인것에 비해 정확도를 많이 떨어지지 않게하였다.
2. tensorflow를 C로 변환할때의 문제
layer를 똑같이 구성했는데도 C에서 결과가 제대로 나오지않았다.
방법1. 정확도 상관없이 최대한 layer와 weight를 줄여보았다. (복잡해서 그러는건지)
방법2. 좌우 반전된 이미지의 문제인가 테스트해보았다. (이미지전처리)
방법3. C에서 함수들의 문제인지 생각해보았다. (2d convolution? 3d convolution?)
방법4. CNN을 지우고 weight와 bias matmul만 진행해보았다. (matmul로만으로는 됐다. convolution의 문제)
방법5. txt에 weight와 bias를 fwrite시 순서의 문제? (가중치가 반대로 곱해지는건지)
결국은 알고리즘 구성의 문제였다.
weight와 bias를 한줄로 변환하다보니 pooling에서 zeor padding을 해서 MAX 값을 찾아야했는데, 그 다음자료를 가지고 pooling을 진행한게 화근이였다.
토의 :
프로젝트를 진행하며 아쉬웠던 부분은 충분한 실험을 하지 못했다는 점이다.
PS 정확도 테스트 중 모델의 구조를 바꾸어 다시 처음부터 실험을 해야 했던 적이 있다.
직접 MNIST를 추출해서 input으로 넣어주었기 때문에 시간부족으로 충분한 실험을 하지 못했고, 98.99%에 완전히 근접하지 못한 96%의 정확도를 얻었다.
또한 PL 부분 수행 시 Vivado HLS로 변환을 수행하였는데, 직접 Network의 병렬적 처리를 구성하여 설계하는 방식으로 진행했다면 더 빠른 연산 속도를 얻을 수 있었을 것이라고 생각한다.
활용분야 :
1. Deep Learning
- High Resolution Video / Image Processing
2. Electric Vehicle
- Lower Power Comsumtion
3. Autonomous Car
- More reliable implementation
4. IoT
- Faster circuit operation
5. Security
- Hardware security module
'대학 활동' 카테고리의 다른 글
| [대학활동] 2020 포트폴리오 전국대회 (4) | 2020.12.26 |
|---|---|
| [대학활동] 2020 캡스톤디자인1 프로젝트 (0) | 2020.12.26 |
| [대학활동] 2020 현장실습인턴 (0) | 2020.12.26 |
| [대학활동] 2019 IDEC SoC 설계과목 이수증 (0) | 2020.12.25 |
| [대학활동] 2019 교내 포트폴리오 경진대회 (0) | 2020.12.25 |

